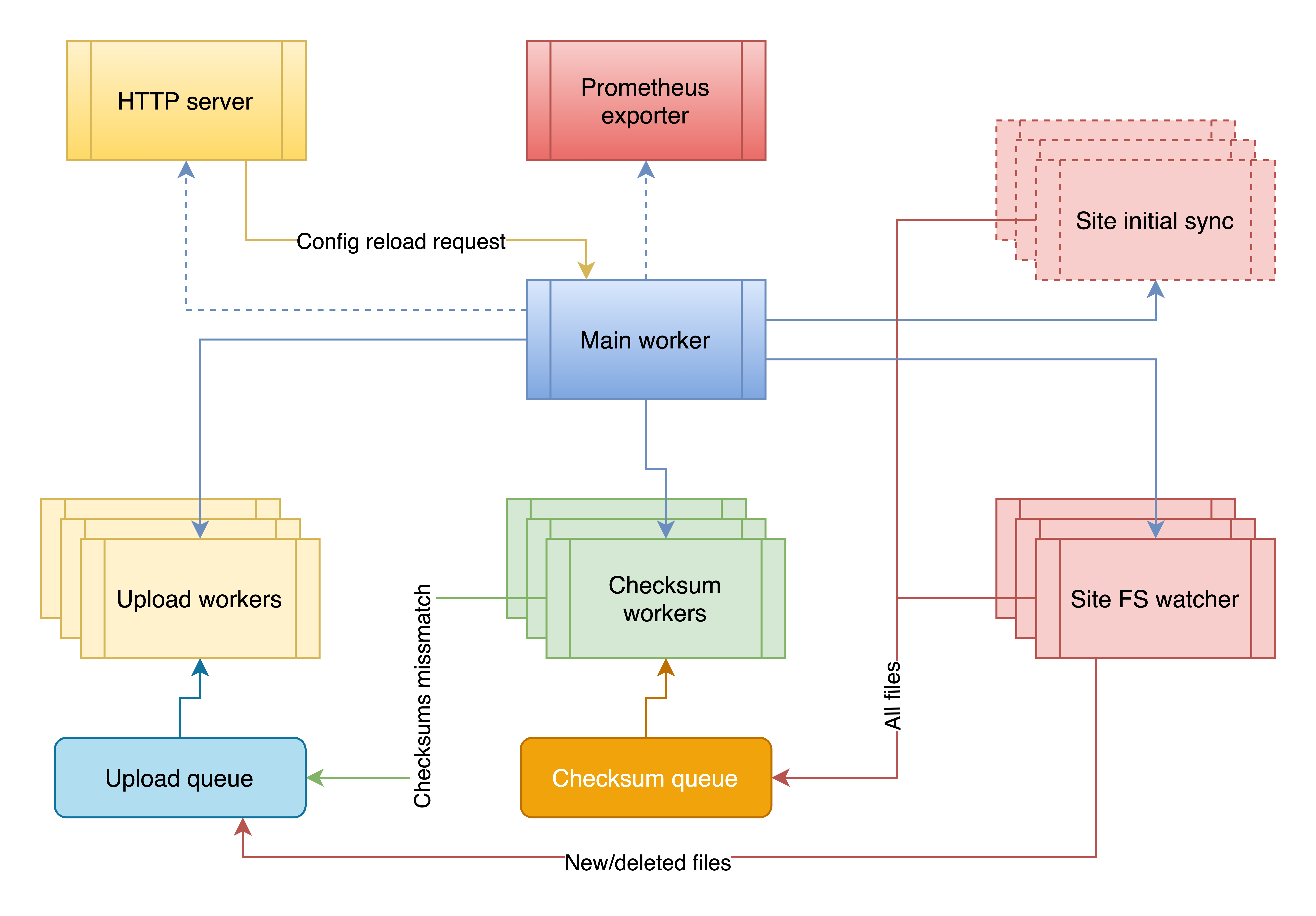
Process flow
On start, the s3sync-service launches pool of generic upload workers, checksum workers and an FS watcher for each site. Once all of the above launched it starts comparing local directory contents with S3 (using checksums<->ETag and also validates StorageClass) which might take quite a while depending on the size of your data directory, disk speed, and available CPU resources. All the new files or removed files (if retire_deleted is set to true) are put into the upload queue for processing. The FS watchers, upload and checksum workers remain running while the main process is working, which makes sure that your data is synced to S3 upon change.
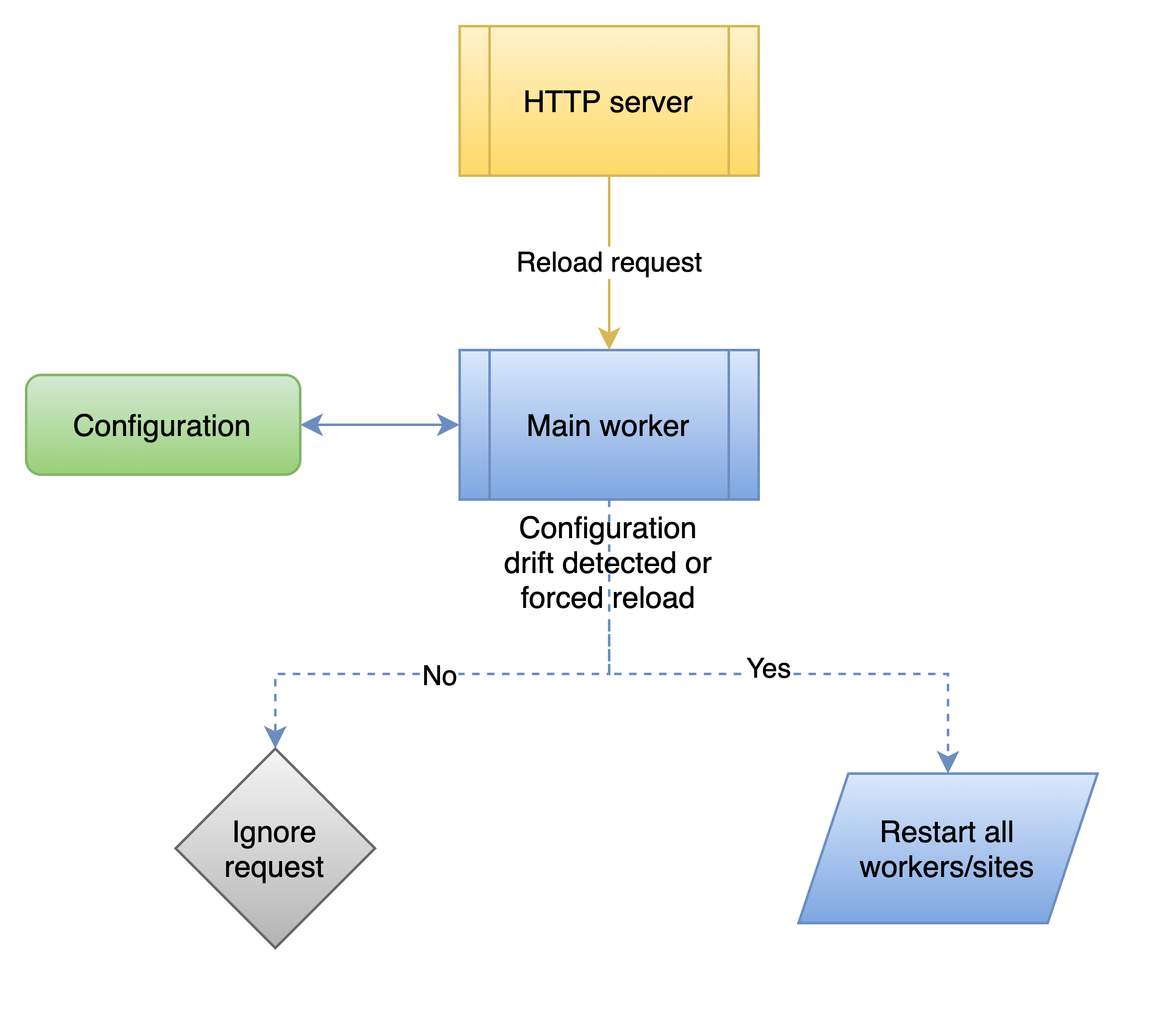
Application reload
At the moment reload can be triggered manually with the following command:
> curl http://127.0.0.1:8090/reload -v
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 8090 (#0)
> GET /reload HTTP/1.1
> Host: 127.0.0.1:8090
> User-Agent: curl/7.64.1
> Accept: */*
>
< HTTP/1.1 200 OK
< Content-Type: application/json
< Server: s3sync-service
< Date: Wed, 04 Nov 2020 00:26:55 GMT
< Content-Length: 87
<
* Connection #0 to host 127.0.0.1 left intact
{"VERSION":"devel","STARTUPTIME":"2020-11-04T01:23:22.335032+01:00","STATUS":"RUNNING"}* Closing connection 0
Most of the configuration options can be changed using the reload apart from those that are set via the command line arguments, logging level can be increased but not decreased.
In k8s environments reload is triggered by configmap changes, check the k8s recipe for more details
There are some preconditions for reloading to be executed:
- an actual configuration drift detected, i.e. current running configuration differs from configmap/config file
- reload is forced with the
forceURL parameter, in this case, configuration drift check is ignored